agi.score leaderboard
Robust all-source benchmark score
A robust LLM ranking calculated from every numeric datapoint in the LiveBench table and the benchmark images hosted on the site: MiMo, Cursor, Google Gemini 3.5, the Anthropic Opus 4.8 launch comparison, NVIDIA Nemotron 3 Ultra, Mythos 5, Cohere North Mini Code, GLM-5.2, VibeThinker 3B, and Rio 3.5 Open.
Updated 16 June 2026
What is scored: LiveBench Global Average plus seven category averages, every numeric MiMo image cell, every numeric Cursor image cell, every numeric cell from the pooled vendor launch comparison tables (Google Gemini 3.5 and Anthropic Opus 4.8), the Artificial Analysis Intelligence Index, and the Liquid AI, StepFun, NVIDIA Nemotron 3 Ultra, Anthropic Mythos 5 / Fable 5, Cohere North Mini Code, GLM-5.2, VibeThinker 3B, and Rio 3.5 Open benchmark cells. The headline score is now robust/source-balanced rather than raw cell-weighted. Rank metrics such as FrontierSWE are inverted so lower ranks score higher.
Missing dashes are excluded from that source/model average rather than treated as zero. Image-derived models are matched to the closest LiveBench variant where the label clearly refers to the same model family.
LiveBench context: objective ground-truth answers, no LLM judge, regularly refreshed questions to limit contamination.
Official source: livebench.ai
Combined Ranking
| # | Model | Organization | agi.score v2 | Legacy | Sources | Cells |
|---|
Methodology
Headline score is agi.score v2. Each benchmark is first converted onto a robust comparable scale instead of forcing every small source table through min-max. Percent metrics use a continuity-corrected logit transform, lower-is-better ranks are inverted, and off-scale point/Elo metrics keep their natural order before robust normalization.
Robust per-benchmark normalization. For each benchmark column, values are centered by the median and scaled by MAD/IQR rather than by the best and worst model in that source. Extreme z-scores are clamped to +/-3 and mapped back to a readable 0-100 score with a sigmoid. This avoids the old failure mode where a tiny four-model launch table automatically gave one model 100 and another 0.
Source-balanced model score. Each source contributes one source score per model, then model scores are averaged across sources rather than cell-weighted across every raw benchmark cell. Evidence confidence is still shown in the final number: confidence = n_eff / (n_eff + 8), where n_eff caps each source at 12 cells, and low-evidence models are shrunk toward 50. The Legacy column preserves the previous raw/min-max cell-weighted score for continuity.
Variant matching and source coverage. Image-derived labels are matched to the closest LiveBench/source equivalent only where the label clearly refers to the same model family or effort setting. Missing dashes remain excluded. Current sources include LiveBench, MiMo, Cursor, vendor launch tables, Artificial Analysis, Liquid AI, StepFun, Nemotron, Mythos, North Mini Code, GLM-5.2, VibeThinker 3B, VibeThinker LeetCode contests, and Rio 3.5 Open.
Source 1 - LiveBench 2026-01-08
| # | Model | Organization | Global | Reasoning | Coding | Agentic | Math | Data | Language | IF | Robust |
|---|
Source 2 - MiMo-V2.5-Pro image comparison
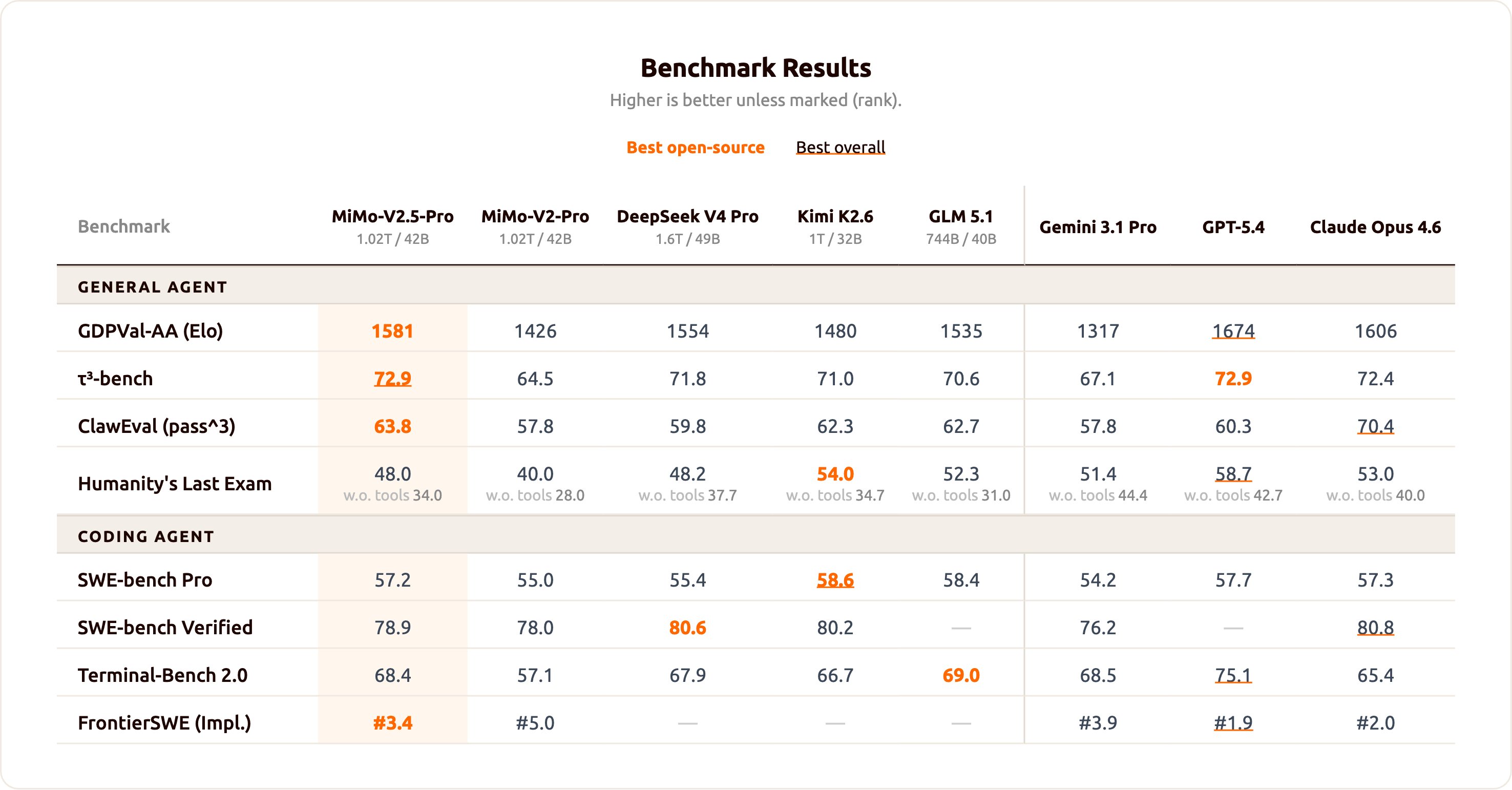
MiMo extracted numeric cells
Source 3 - Cursor Composer 2.5 image comparison
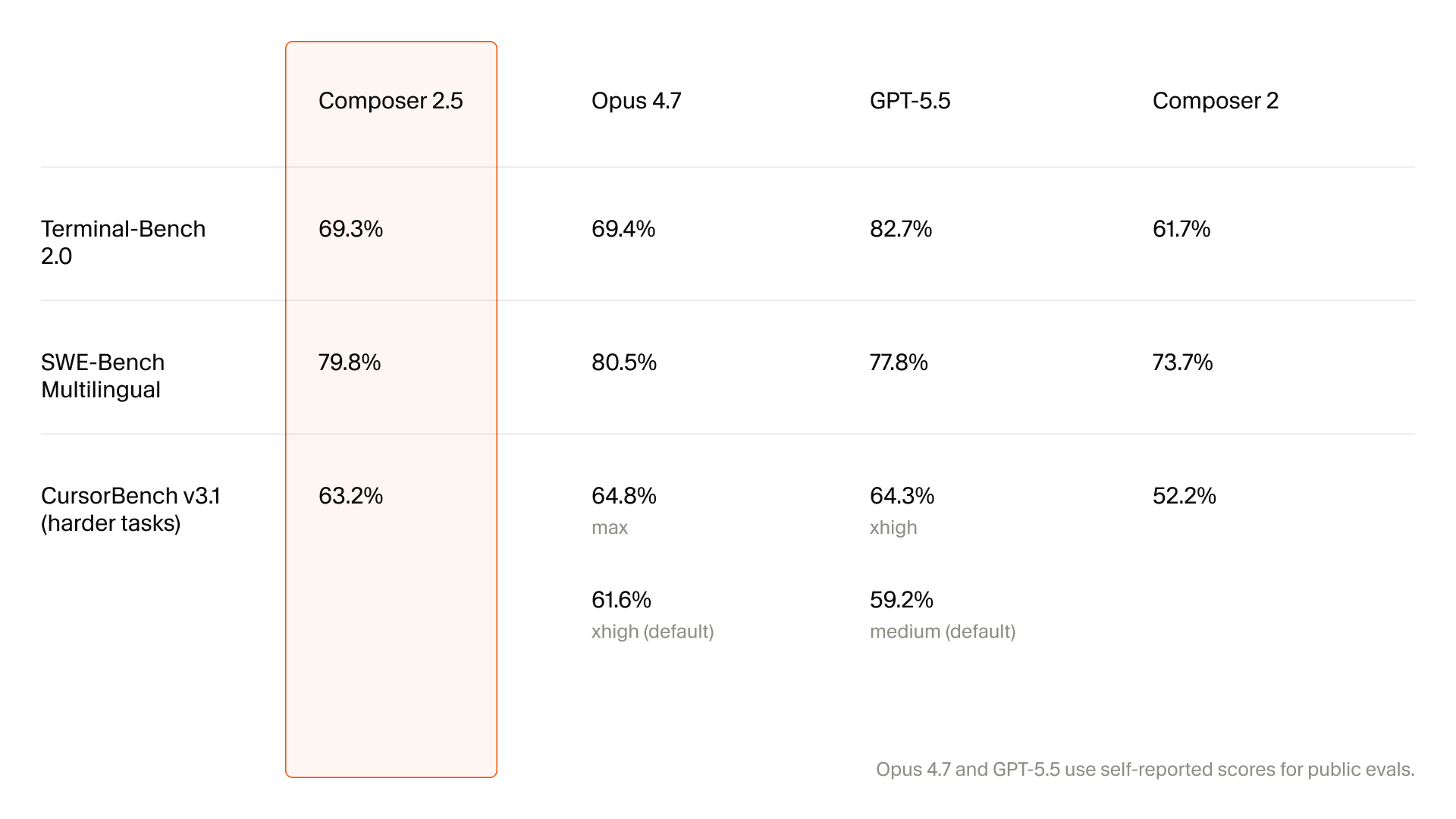
Cursor extracted numeric cells
Source 4 - Vendor launch benchmark tables
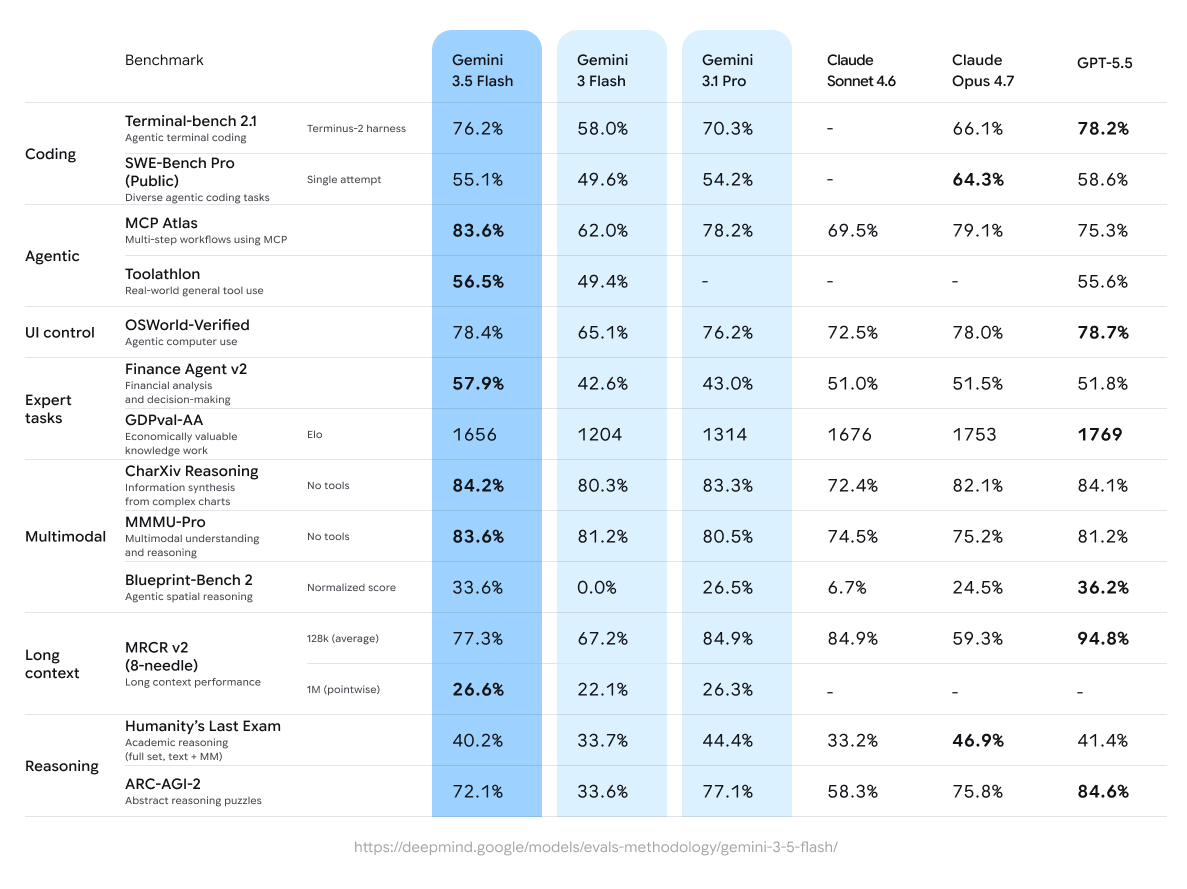
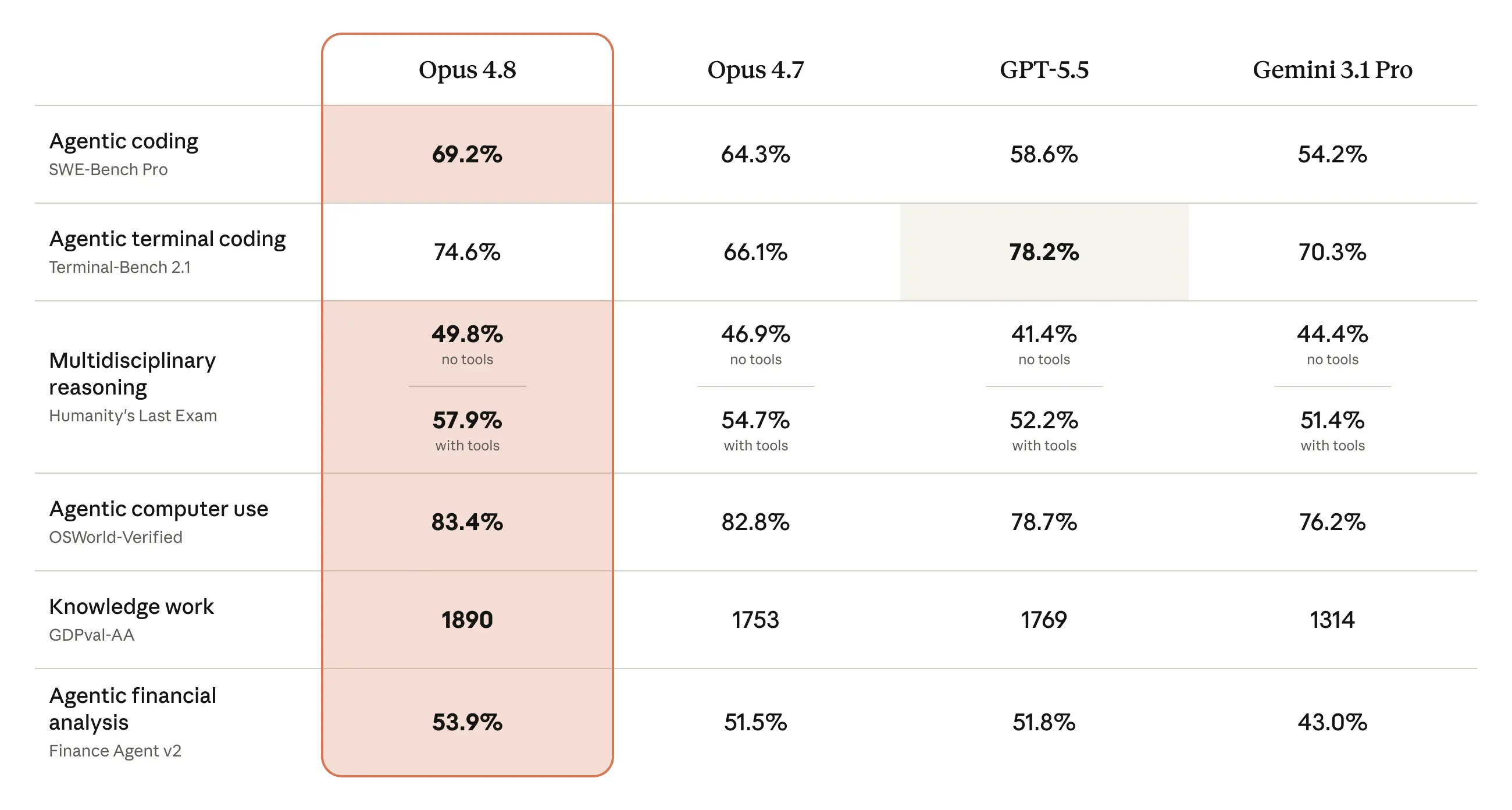
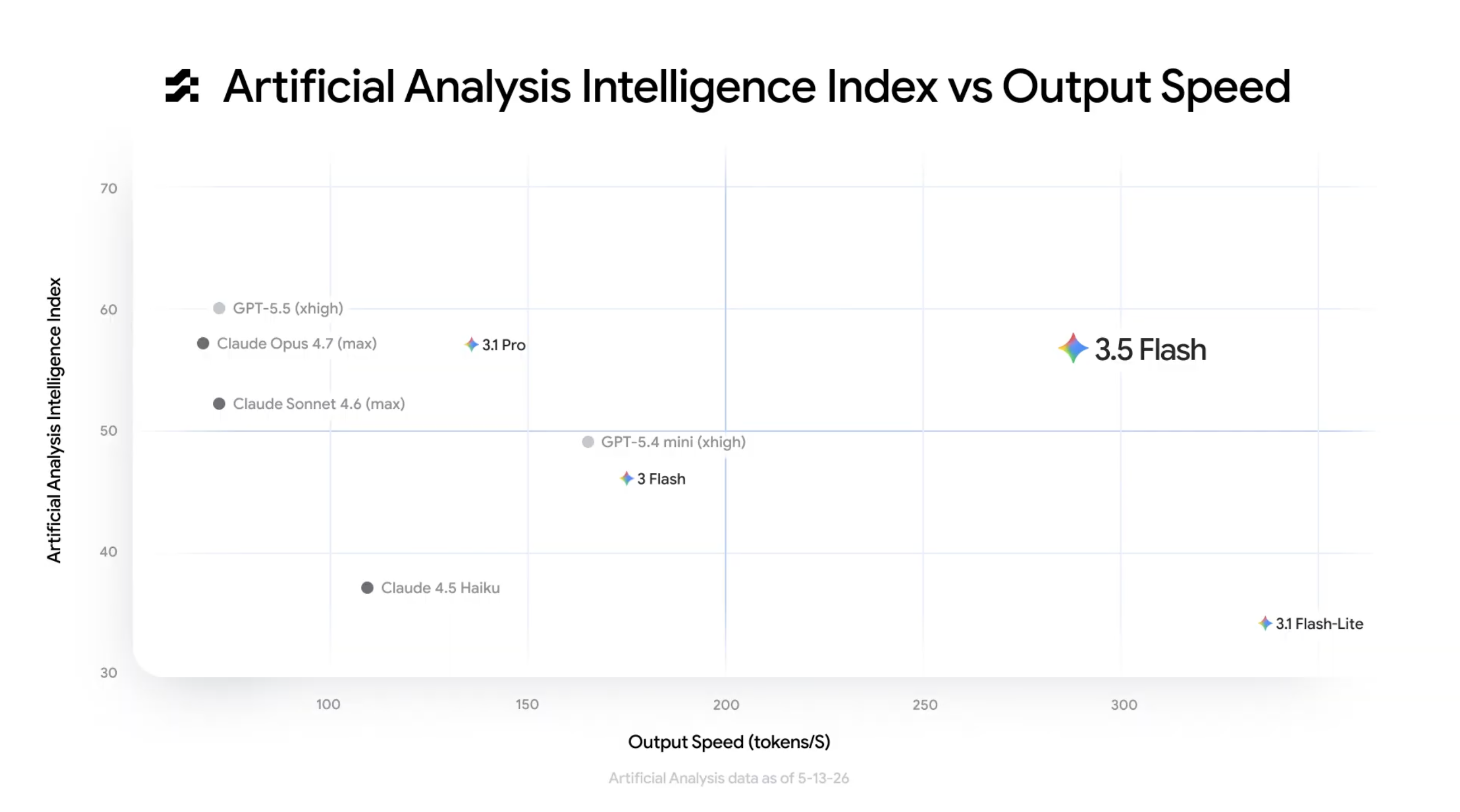
Pooled launch-table numeric cells
Source 5 - Artificial Analysis Intelligence Index
Artificial Analysis extracted numeric cells
Source 6 - Liquid AI LFM2.5-8B-A1B benchmarks
LFM2.5 extracted numeric cells
Source 7 - StepFun Step 3.7 Flash benchmarks
Step 3.7 Flash extracted numeric cells
Source 8 - NVIDIA Nemotron 3 Ultra keynote comparison

Nemotron 3 Ultra extracted numeric cells
Source 9 - Anthropic Claude Mythos 5 / Fable 5 launch comparison
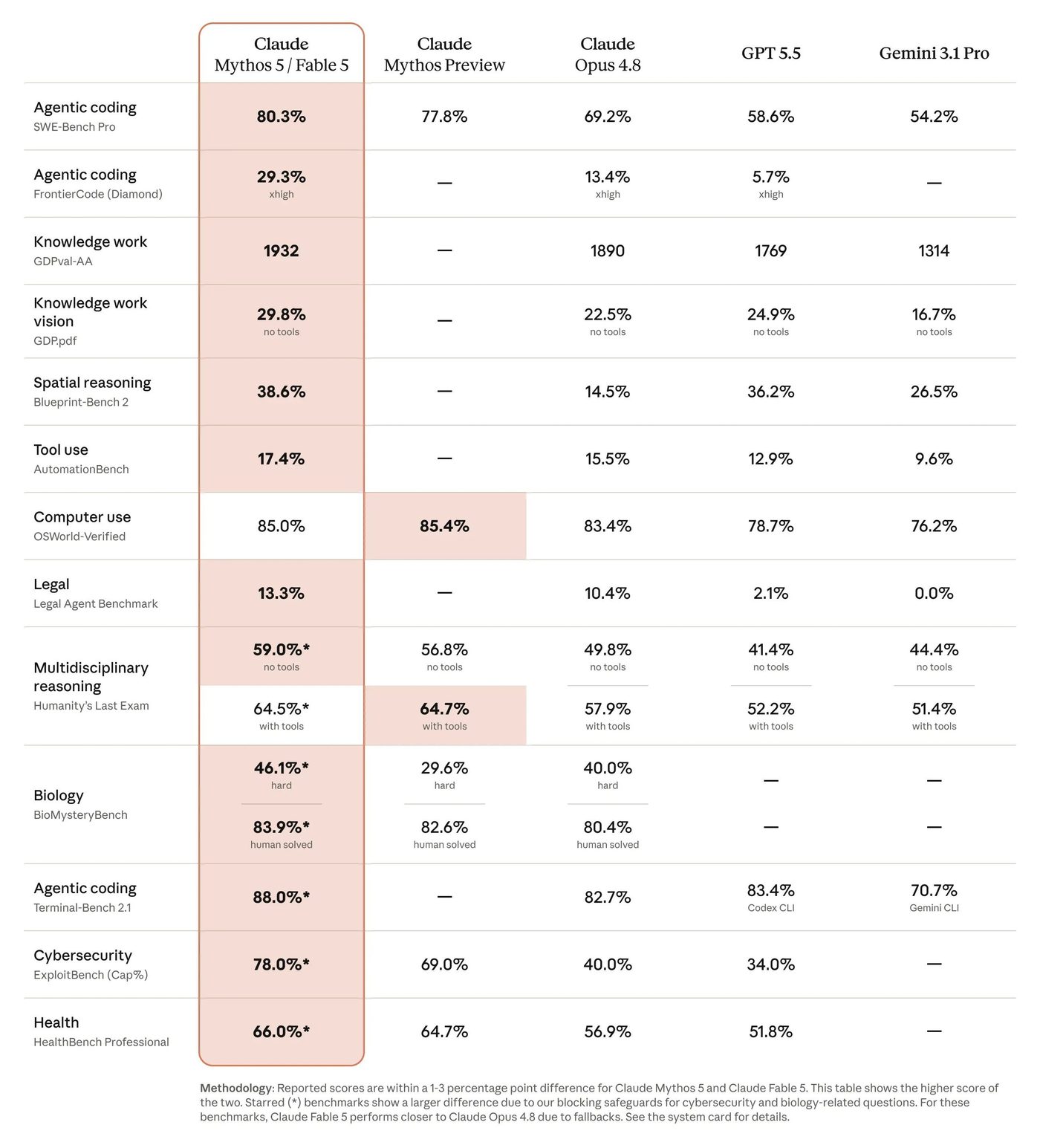
Mythos 5 extracted numeric cells
Source 10 - Cohere North Mini Code image comparison
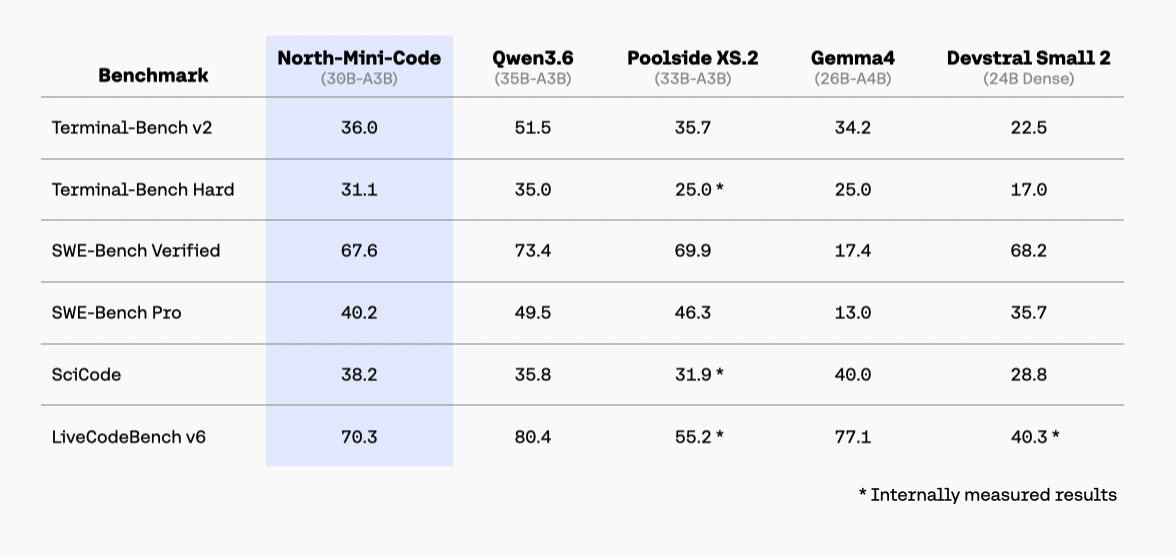
North Mini Code extracted numeric cells
Source 11 - Z.ai GLM-5.2 image comparison
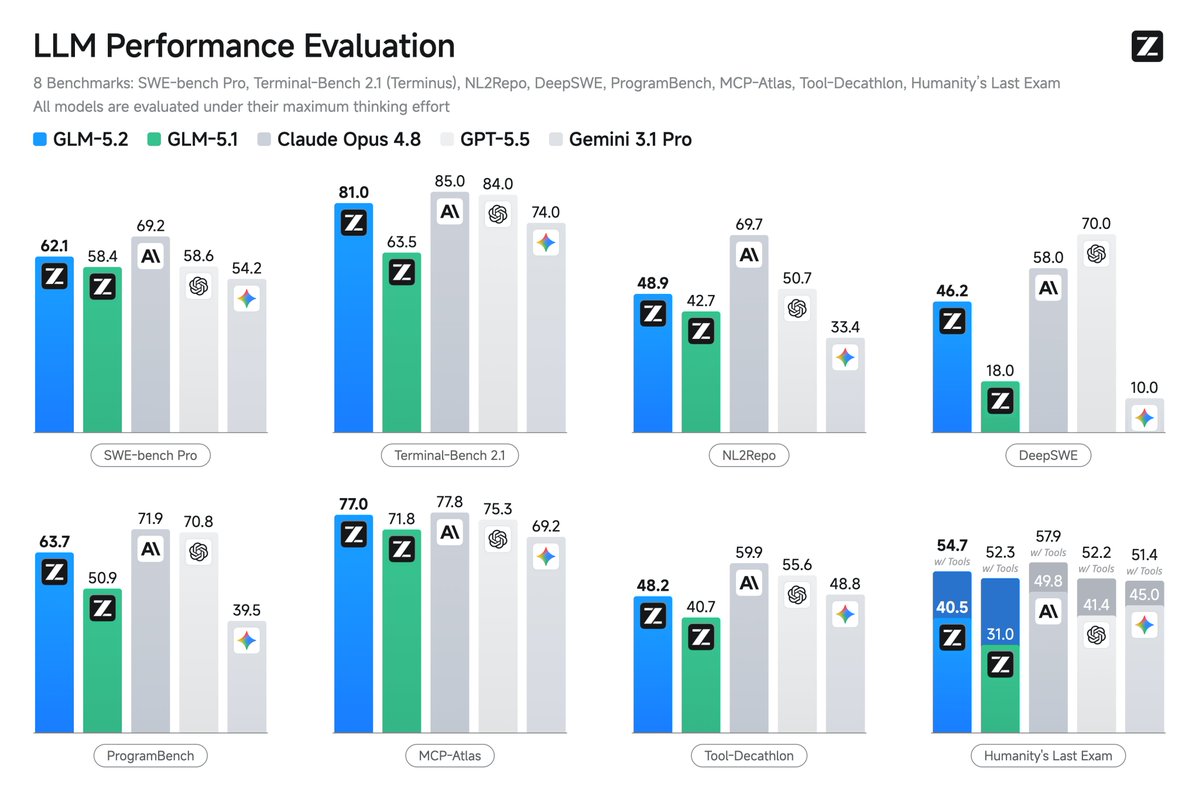
Z.ai GLM-5.2 extracted numeric cells
Source 12 - VibeThinker 3B reasoning image comparison
IMO-AnswerBench frontier band
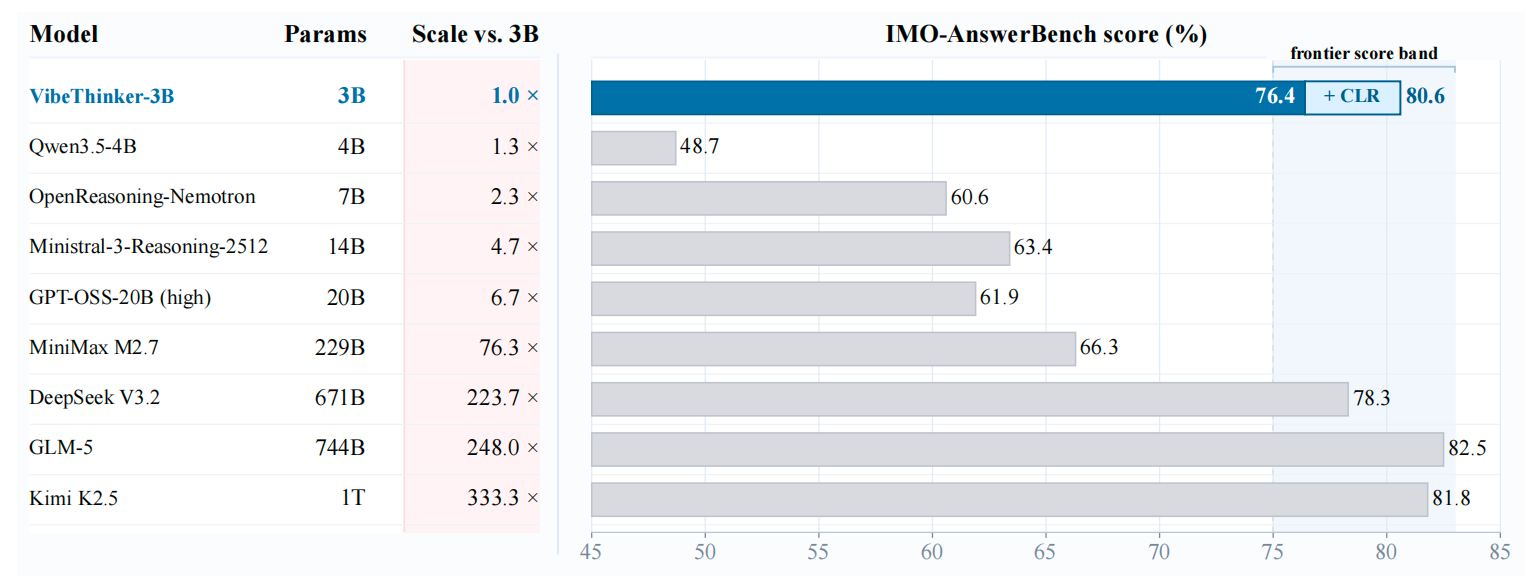
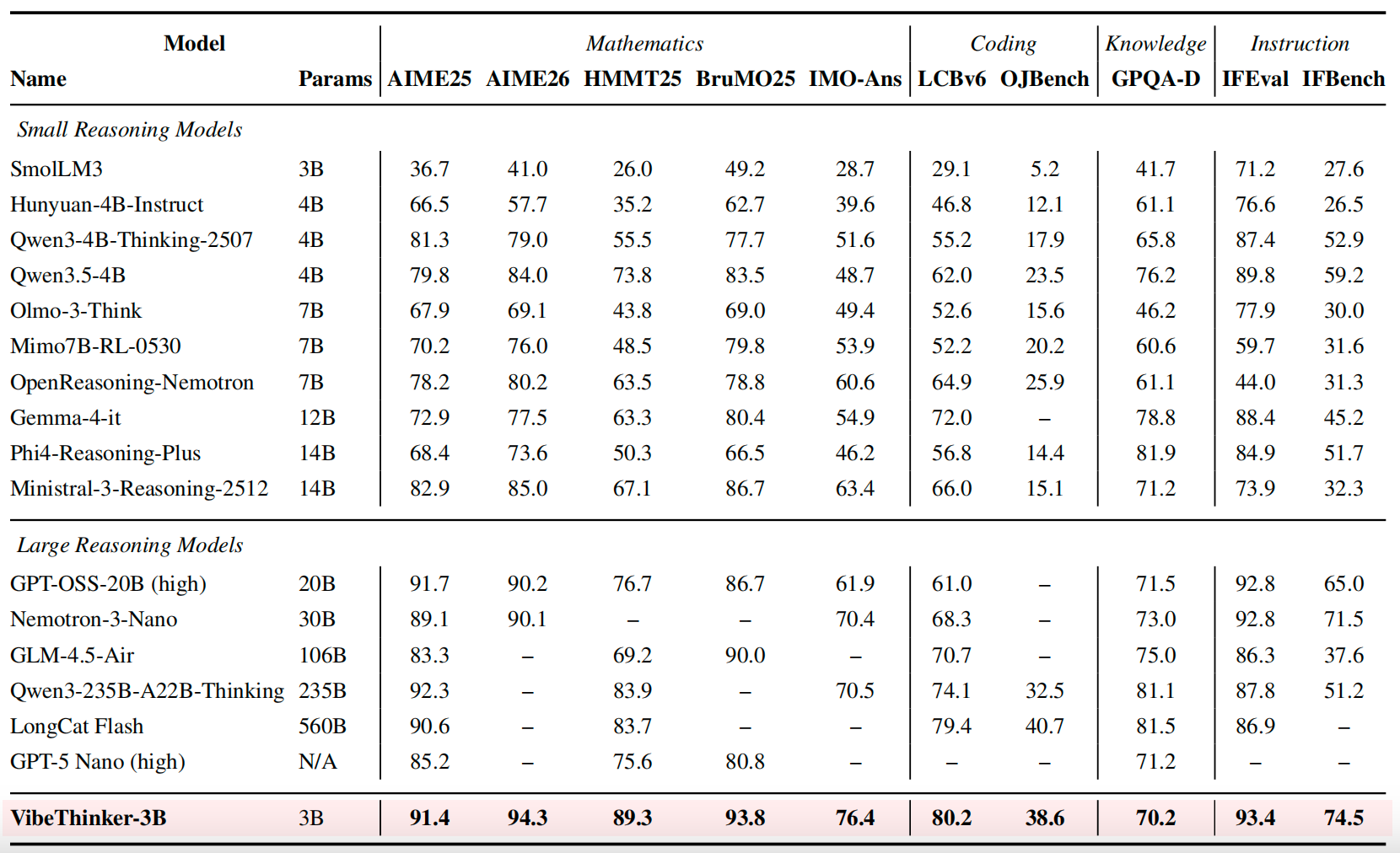
Small and large reasoning tables
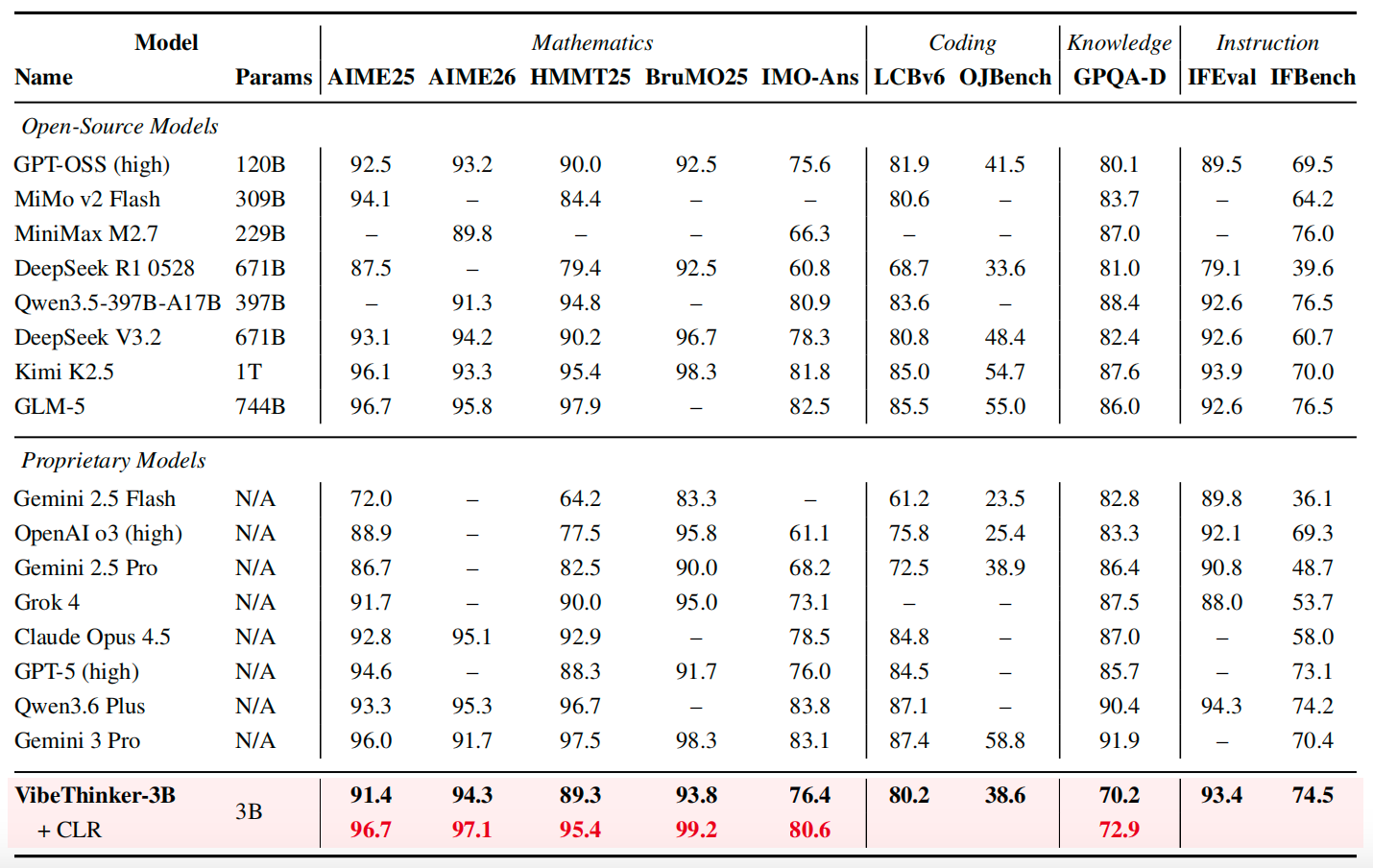
Open-source and proprietary comparison
VibeThinker reasoning extracted numeric cells
Source 13 - VibeThinker 3B LeetCode contest image comparison
LeetCode contests (Python)
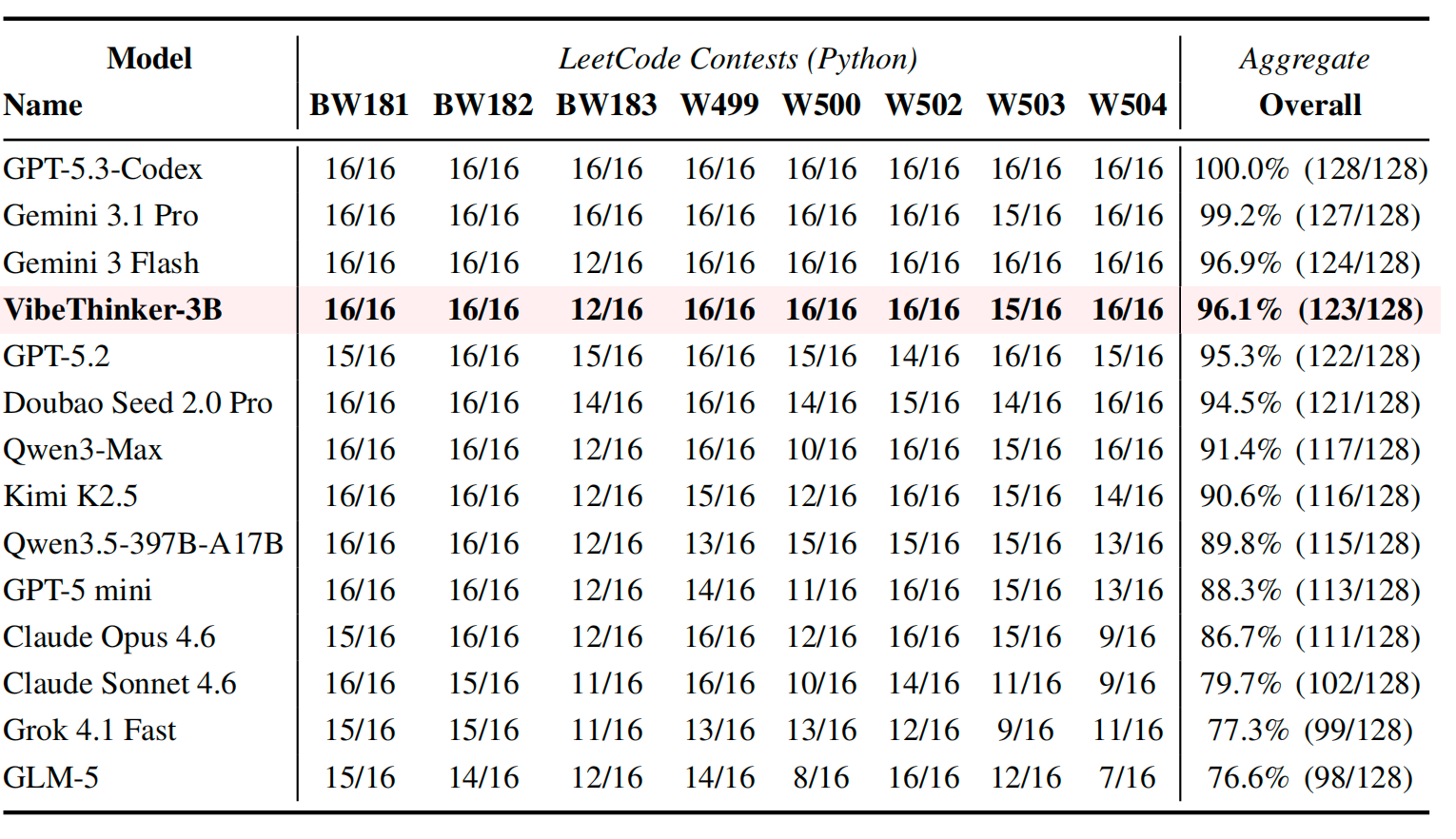
VibeThinker LeetCode extracted numeric cells
Source 14 - Rio 3.5 Open 397B image comparison
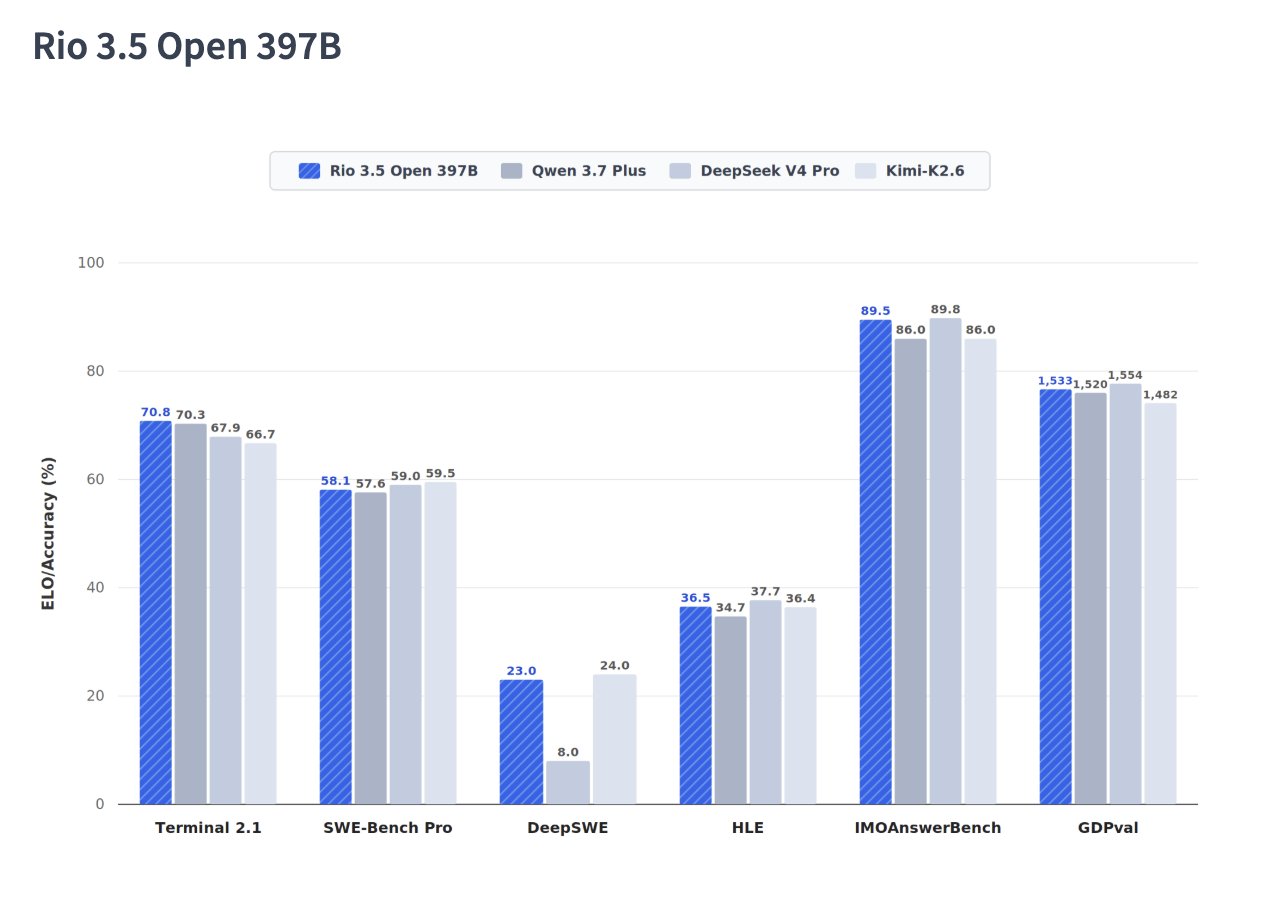
Rio 3.5 Open 397B extracted numeric cells
Citation
@inproceedings{livebench,
title={LiveBench: A Challenging, Contamination-Free {LLM} Benchmark},
author={Colin White and Samuel Dooley and Manley Roberts and Arka Pal and Benjamin Feuer and Siddhartha Jain and Ravid Shwartz-Ziv and Neel Jain and Khalid Saifullah and Sreemanti Dey and Shubh-Agrawal and Sandeep Singh Sandha and Siddartha Venkat Naidu and Chinmay Hegde and Yann LeCun and Tom Goldstein and Willie Neiswanger and Micah Goldblum},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
}